






Recently I was writing a “tips and tricks” blog post that was going to focus on the idea that it is better to use an object as a “string buffer”; the idea was that by passing this object around to various functions and pushing string fragments into it, you can get better performance from a JavaScript engine. My friend and colleague Alex Russell challenged me to show him hard data supporting this hypothesis—and the results were quite eye-opening!

For this analysis, I used two sources for tests: the dojox.string.Builder Builder performance test, and a custom test implementing three versions of a common JavaScript task: a JSON Serializer. The initial concept was to show that pushing strings into an object buffer would be faster than using the simple JavaScript operations available to any developer.
Background: String Theory.
From my friend and colleague Eugene Lazutkin comes this excellent explanation about strings in programming:
Many modern languages (especially functional languages) employ “the immutable object” paradigm, which solves a lot of problems including the memory conservation, the cache localization, addressing concurrency concerns, and so on. The idea is simple: if object is immutable, it can be represented by a reference (a pointer, a handle), and passing a reference is the same as passing an object by value — if object is immutable, its value cannot be changed => a pointer pointing to this object can be dereferenced producing the same original value. It means we can replicate pointers without replicating objects. And all of them would point to the same object. What do we do when we need to change the object? One popular solution is to use Copy-on-write (COW). Under COW principle we have a pointer to the object (a reference, a handle), we clone the object it points to, we change the value of the pointer so now it points to the cloned object, and proceed with our mutating algorithm. All other references are still the same.
JavaScript performs all of “the immutable object” things for strings, but it doesn’t do COW on strings because it uses even simpler trick: there is no way to modify a string. All strings are immutable by virtue of the language specification and the standard library it comes with. For example: str.replace(“a”, “b”) doesn’t modify str at all, it returns a new string with the replacement executed. Or not. If the pattern was not found I suspect it’ll return a pointer to the original string. Every “mutating” operation for strings actually returns a new object leaving the original string unchanged: replace, concat, slice, substr, split, and even exotic anchor, big, bold, and so on.
The issue is usually string operations come with a “hidden cost”; because strings are (in theory) immutable, we would expect that any kind of string mutation will come with the costs of copy and replace, taking up valuable CPU cycles, consuming memory space, and putting strains on a garbage collector (among other things). A typical technique used in many languages is to use something you can pass by reference (like an object or array) to your methods, and push string fragments into that—delaying the cost of string mutation until it is absolutely needed. In fact, this was the exact reason I wrote the original dojox.string.Builder; I borrowed the idea from C# as a way of increasing efficiency for large string operations, such as building a document fragment on the fly or serializing a JavaScript Object Literal.
(A side note: the original has gone through quite a few iterations, the latest one by Ben Lowery, who was initially using Builder extensively with Bloglines.)
After doing some fairly extensive testing, I learned that with the modern browsers, this is not the case at all; in fact, not only were typical string operations optimized cross-browser but the performance of dojox.string.Builder was dismal, particularly when compared against native operations.
Round 1: Measuring Native Operations.
The chart at the top of this article is the summary of native operation performance. All tests were done on a MacBook Pro 2.4Ghz Core 2 Duo, with 4GB of installed RAM; tests were run on both OS X and on Windows 2003 Server running under Parallels Desktop (with enough RAM allocated to ensure consistent results).
The first set of tests run was based on the tests made by Ben Lowery (the BuilderPerf test, see link above), using a Lorem Ipsum dictionary with the default numbers (1000 iterations using 100 words). The basic concept is to test performance based on both one-time and iterative operations. As an example, here are the tests for concat() once and concat() for:
{
name: "concatOnce",
test: function() {
var s = "";
s = String.prototype.concat.apply(s, words);
return s;
}
},
{
name: "concatFor",
test: function(){
var s = "";
for(var i=0; i<words.length; i++){
s = s.concat(words[i]);
}
return s;
}
}
…where the variable words is the dictionary initially generated used for all the tests.
The results were about what we would expect: one time operations in general executed much faster than iterative ones. Here’s the chart again:
One interesting result: the += operator on strings is actually faster, across the board, than [string].concat().
Taking a closer look, we can also accurately gauge performance by browser. For example, comparing the major browsers with the once operations:
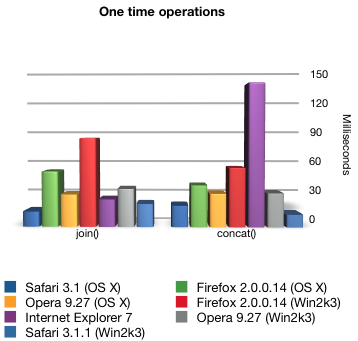
…we can see that the two most common browsers, Internet Explorer and Firefox (under Windows) have some issues; join performance with Firefox is not great but concat performance with Internet Explorer is absolutely dismal.
However, one time operations such as these—while attractive and certainly the best performing—are not nearly as common as operations made during some sort of iteration. Here’s the comparison of major browsers using the three most common operations during iteration (join, concat and the “+=” operator):

We can draw a few conclusions from this particular chart:
- The += operator is faster—even more than pushing string fragments into an array and joining them at the last minute
- An array as a string buffer is more efficient on all browsers, with the exception of Firefox 2.0.0.14/Windows, than using String.prototype.concat.apply.
The performance of dojox.string.Builder was also measured with this battery of tests; we’ll present that data later in the article.
Round 2: Comparing types of buffering techniques.
The second round of tests was performed using three slightly different versions of a typical JSON serializer, based on the one used in the Dojo Toolkit. The serializer has three versions:
- Recursive serialization using += (passing strings as the result of a function)
- Recursive serialization using local arrays as buffers (created internally to a function)
- Serialization using a single array passed to methods as an argument with no return (i.e. void)
The test takes a large pre-loaded Javascript Object Literal structure (the serialized version weighs in at 19,200 characters), and serializes it using all three serializers 10 times, taking the average result. Each test is run 5 times in succession. Finally, 20 samples were taken for each browser.
The expectation was that a single object as a string buffer would yield better performance results, consistently across browsers.
Results
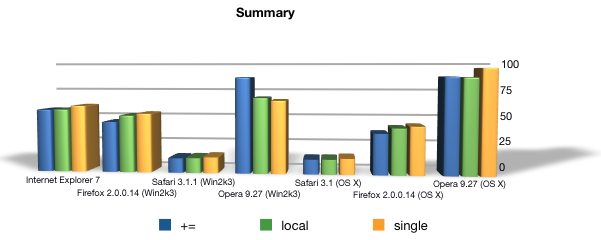
In all cases (with the exception of Opera 9.27/Win), using a single object as a string buffer performed the worst, with the best general performance coming from using recursive serialization with the “+=” operator.
Comparing Browsers
To shed a little further light—and to accurately gauge the performance of each browser—we can compare each serialization technique:
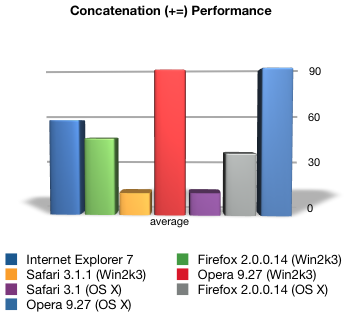


As detailed elsewhere, Safari (on both OS X and Windows) is by far the fastest executing browser; unexpectedly, Opera 9.27—which historically has an excellent track record in terms of performance—was the least performant in these tests. Also of interest is the fact that the cross-platform browsers (Safari, Firefox and Opera) remain fairly consistent in terms of actual performance.
Round 3: Applying Results to dojox.string.Builder.
With the results of both rounds available, an analysis of the performance of dojox.string.Builder was undertaken. Performance numbers (pre-optimization) were captured during the first battery of tests, revealing a number of issues with the Builder.append method (by far the most commonly used method). However, some investigation and testing resulted in up to a 10x increase in performance—in some cases, being either comparable to or even beating certain browser operations!

Because of the very good performance in Safari and Opera, the goal of the optimization process was to address shortcomings in both Internet Explorer and Firefox.
Finding the culprits
Carefully analyzing the original code with dojox.string.Builder.append:
append: function(s){
return this.appendArray(dojo._toArray(arguments));
}
…we determined that a number of things were causing performance issues:
- The call to dojo._toArray, with the arguments object
- Passing the results to dojox.string.Builder.appendArray, without testing first for a shorter branch
- Dynamic arguments object access
Optimization 1: Addressing the Simplest Case.
The first change made introduced a branch, for all browsers, that checks to see if more than one argument was passed.
append: function(s){
if(arguments.length>1){
return this.appendArray(dojo._toArray(arguments));
} else {
this.b += s;
return this;
}
}By performing this simple check, we eliminate the need for calling both dojo._toArray as well as the passthrough to the method appendArray. This change increased the performance of the append method with dramatic results—referring to the chart above, this was by far the greatest performance enhancer.
However, when passing multiple arguments to the append method, both Internet Explorer and Firefox slowed down dramatically.
Optimization 2: Fixing Internet Explorer
The internal string buffer used for Internet Explorer is different than any other browser; based on the test results from our first round, we know that pushing string fragments into an array and then join-ing them only when a complete string is needed is the best method for string handling.
Knowing that the culprit for real performance issues is the call to dojo._toArray with the arguments object, the goal was to eliminate the need for using it. One simple way to deal would be to simply iterate through the arguments and append each one, one by one:
append: function(s){
if(arguments.length>1){
for(var i=0, l=arguments.length; i < l; i++){
this.b.push(arguments[i]);
}
} else {
this.b.push(s);
}
return this;
}This helped a bit, but there was not a dramatic increase in performance. To eek a bit more out of the method, we tested the difference between using [].push and manually specifying the next available index in the array; we found that specifying the next available index was a bit faster. Finally, we resorted to an implementation of Duff’s Device, a technique for loop unrolling. Here’s the final code:
append: function(s){
if(arguments.length>1){
// Some Duff's device love here.
var n = Math.floor(arguments.length/8), r = arguments.length%8, i=0;
do {
switch(r){
case 0: this.b[this.b.length]=arguments[i++];
case 7: this.b[this.b.length]=arguments[i++];
case 6: this.b[this.b.length]=arguments[i++];
case 5: this.b[this.b.length]=arguments[i++];
case 4: this.b[this.b.length]=arguments[i++];
case 3: this.b[this.b.length]=arguments[i++];
case 2: this.b[this.b.length]=arguments[i++];
case 1: this.b[this.b.length]=arguments[i++];
}
r = 0;
} while(--n>0);
} else {
this.b[this.b.length]=s;
}
return this;
}This loop unroll brought the performance of append with multiple arguments down to the same, or faster, than using append with a single argument multiple times.
Optimization 3: Fixing Firefox.
The last set of optimizations involved fixing the dismal performance in Firefox. Like with Internet Explorer, Firefox had major problems when using dojo._toArray, so the first order of business was to move iterating over the arguments object within the append method itself:
append: function(s){
if(arguments.length>1){
var i=0;
while(i < arguments.length){
this.b += arguments[i++];
}
} else {
this.b += s;
}
return this;
}What this revealed was that accessing members of the arguments object seemed to be very slow—to the point where just iterating over each argument caused enough of a performance hit to actually decrease the performance over using dojo._toArray!
With that in mind, and the help of my colleague Kris Zyp, what we determined was that the issue in Firefox isn’t so much that accessing members of the arguments object is the issue; it’s that dynamic access of the arguments object is the problem. With that in mind, a different kind of loop unroll was called for:
append: function(s){
if(arguments.length>1){
var tmp="", l=arguments.length;
switch(l){
case 9: tmp=arguments[8]+tmp;
case 8: tmp=arguments[7]+tmp;
case 7: tmp=arguments[6]+tmp;
case 6: tmp=arguments[5]+tmp;
case 5: tmp=arguments[4]+tmp;
case 4: tmp=arguments[3]+tmp;
case 3: tmp=arguments[2]+tmp;
case 2: {
this.b+=arguments[0]+arguments[1]+tmp;
break;
}
default: {
var i=0;
while(i < arguments.length){
this.b += arguments[i++];
}
}
}
} else {
this.b += s;
}
return this;
}With this unrolling technique, we accomplish the following:
- We create a temporary string buffer (tmp)
- We take advantage of Javascript’s fall-through switch…case structure to deal with up to 9 arguments
- We specify in each case branch the actual argument number
- We prepend the argument to the temporary buffer
- …finally appending the result to the internal buffer (this.b).
This unroll did not noticeably affect the performance of either Safari or Opera, but made a huge difference with Firefox; from the chart above, you can see close to a 10x increase in performance with both the Windows and OS X versions of Firefox. Note that passing more than 9 arguments will cause Firefox to fall back to the dynamic arguments access version; in theory we can simply add more case statements to deal with this, but from a practical standpoint 9 arguments should be a good limit.
Comparing dojox.string.Builder Performance with Native Operations
Finally, we should compare how the new optimized version of dojox.string.Builder compares to the native operations we analyzed in Rounds 1 and 2. Again, the tests (including a new one that tested the performance of Builder.append with mulitple arguments) were run, as they were with Round 1—this time with the optimized Builder.

With Safari and Opera, dojox.string.Builder is still slightly slower when used in iterative situations; however, the difference is close enough so that one should not find a noticeable decrease in performance when using it. With Internet Explorer, we find that the performance of the Builder is still pretty bad when compared to native operations.
However, with Firefox, the only operation faster than using Builder.append is the “+=” operator; both join and concat are close enough to Builder.append that it makes no difference which version you use.
Conclusions
Though this analysis, a number of things about string performance have been observed:
- Native string operations in all browsers have been optimized to the point where borrowing techniques from other languages (such as passing around a single buffer for use by many methods) is for the most part unneeded.
- Array.join still seems to be the fastest method with Internet Explorer; either += or String.prototype.concat.apply(“”, arguments) work best for all other browsers.
- Firefox has definite issues with accessing argument members via dynamic/variables
- And of course, the reminder to not ignore the data